Distribution
Dataset Overview
Download Links

- Baidu Drive: Link
Yansheng Li, Yuning Wu, Gong Cheng, Chao Tao, Bo Dang, Yu Wang, Jiahao Zhang, Chuge Zhang, Yiting Liu,
Xu Tang, Jiayi Ma, and Yongjun Zhang
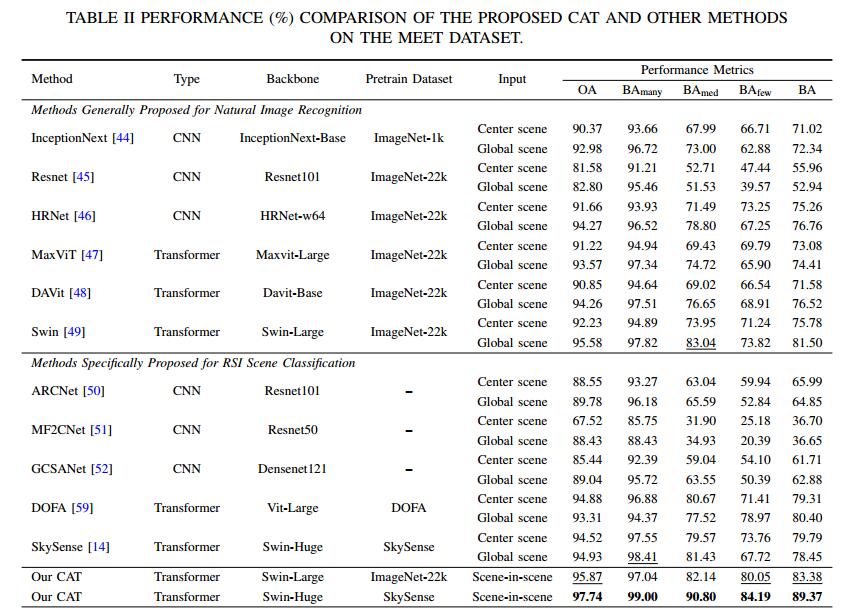
Accurate fine-grained geospatial scene classification using remote sensing imagery is essential for a wide range of applications. However, existing approaches often rely on manually zooming remote sensing images at different scales to create typical scene samples. This approach fails to adequately support the fixed-resolution image interpretation requirements in real-world scenarios. To address this limitation, we introduce the Million-scale finE-grained geospatial scEne classification dataseT (MEET), which contains over 1.03 million zoom-free remote sensing scene samples, manually annotated into 80 fine-grained categories. In MEET, each scene sample follows a scene-in-scene layout, where the central scene serves as the reference, and auxiliary scenes provide crucial spatial context for fine-grained classification. Moreover, to tackle the emerging challenge of scene-in-scene classification, we present the Context-Aware Transformer (CAT), a model specifically designed for this task, which adaptively fuses spatial context to accurately classify the scene samples. CAT adaptively fuses spatial context to accurately classify the scene samples by learning attentional features that capture the relationships between the center and auxiliary scenes. Based on MEET, we establish a comprehensive benchmark for fine-grained geospatial scene classification, evaluating CAT against 11 competitive baselines. The results demonstrate that CAT significantly outperforms these baselines, achieving a 1.88% higher balanced accuracy (BA) with the Swin-Large backbone, and a notable 7.87% improvement with the Swin-Huge backbone. Further experiments validate the effectiveness of each module in CAT and show the practical applicability of CAT in the urban functional zone mapping.
Fig. (a) shows that the existing FGSC dataset forms typical scene samples by manually zooming remote sensing images at different rates. In Fig. (b), the center scene outlined in red, is the basic unit for classification, while the surrounding scene outlined in green and global scene outlined in blue serve as auxiliary contextual images. With zoom-free samples and auxiliary scenes, MEET addresses inter-class and intra-class confusion in zoom-free image samples. Fig. (c) shows remote sensing image scene sample in MEET with the scene-in-scene layout. For the samples from first row and second row, models fail to predict the fine-grained scene category using only the center scene but has a great potential to obtain the right fine-grained scene category using both the center scene and the auxiliary scenes.
MEET dataset is comprised of over 1.03 million sample annotation pairs, encompassing 80 fine-grained scene categories. Samples are collected globally and include multi-level spatial context information. The large sample size, the granularity of categories, and the inclusion of spatial context imagery make MEET a valuable dataset.
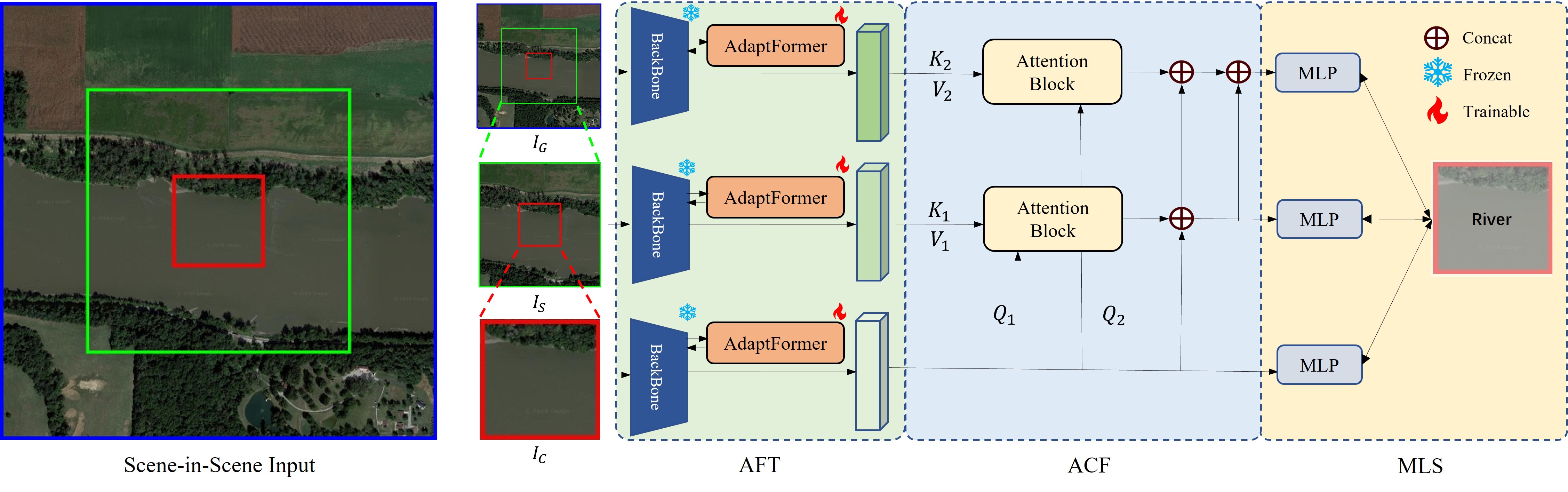
To flexibly and efficiently exploit the scene-in-scene layout in FGSC with zoom-free RSI, this paper introduces CAT, a novel approach specifically tailored for this task. CAT incorporates an adaptive context fusion module to effectively extract multi-scale contextual features from the transformer backbone. To ensure performance without excessively increasing parameters, we utilize parameter-efficient fine-tuning (PEFT) methods to finetune the backbone, instead of training from scratch or parameter synchronization. Additionally, we introduce multi-level supervision through independent classification heads during training. This improves feature learning at each level and mitigates overfitting that can arise from auxiliary scenes.
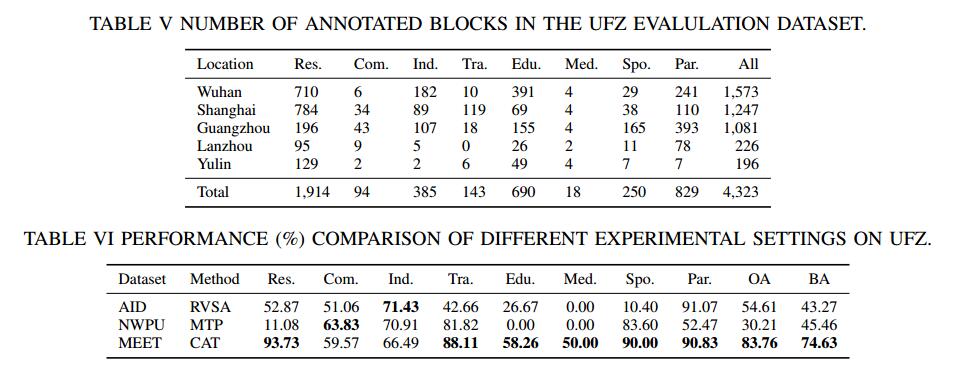
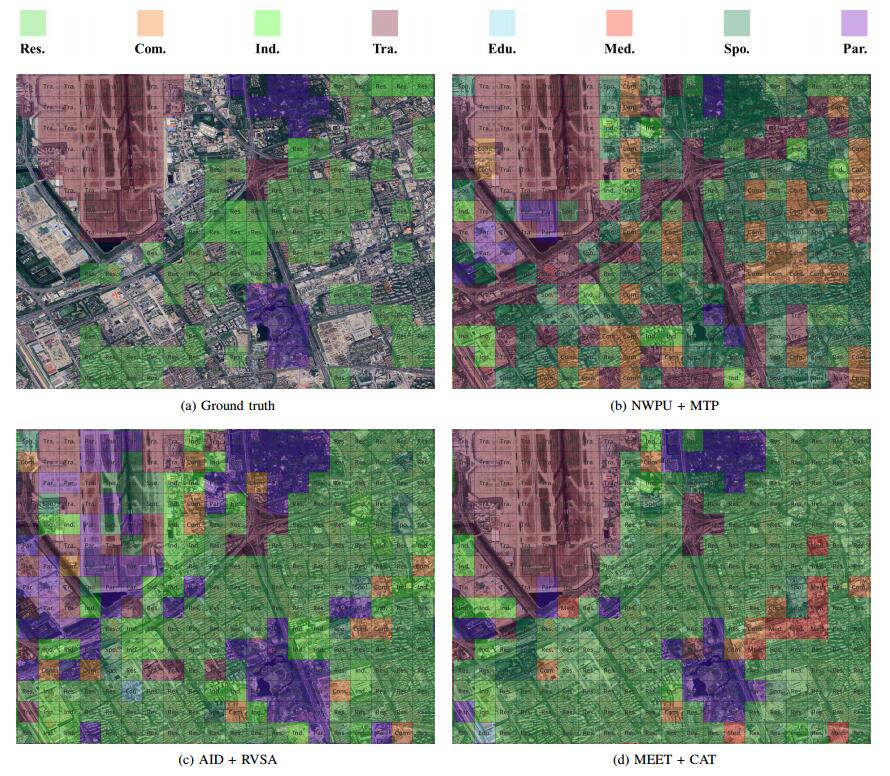
To validate the the setting superiority of the zoom-free characteristic and scene-in-scene sample layout of our MEET dataset, we conduct experiments on urban functional zone mapping (UFZ). In the pilot application, UFZ aims to predict the land-use category of each fixed-resolution RSI block and considers 8 land-use categories.

If you find this work helpful for your research, please consider citing our paper:
Y. Li, Y. Wu, G. Cheng, C. Tao, B. Dang, Y. Wang, J. Zhang, C. Zhang, Y. Liu, X. Tang, J. Ma, and Y. Zhang, “MEET: A million-scale dataset for fine-grained geospatial scene classification with zoom-free remote sensing imagery,” IEEE/CAA J. Autom. Sinica, vol. 12, no. 5, pp. 1004–1023, May 2025. doi: 10.1109/JAS.2025.125324